空间的扩展
当交易越来越普及,区块链里的账本也会越来越大。为了保持系统的信任和公平,不能轻易删除这些信息。还好在比特币最早的设计里已经考虑到这种情况,设计了Merkel Tree的分叉树存储结构。交易挂在Merkle Tree的叶子节点,从叶子节点往上每一层的数值都是下面关联子节点的组合哈希值。一层一层最后所有的节点汇集到一起,最后得到的哈希值就是Merkle Root。比特币每10分钟一个的区块block只需将这个Merkle Root保存到区块头(block Header)即可。对历史交易复查验证的时候,将需要验证的交易信息从叶节点往上追溯,只要追到认证的Merkle Root即可。所以这种方式是一种用计算时间换空间的置换。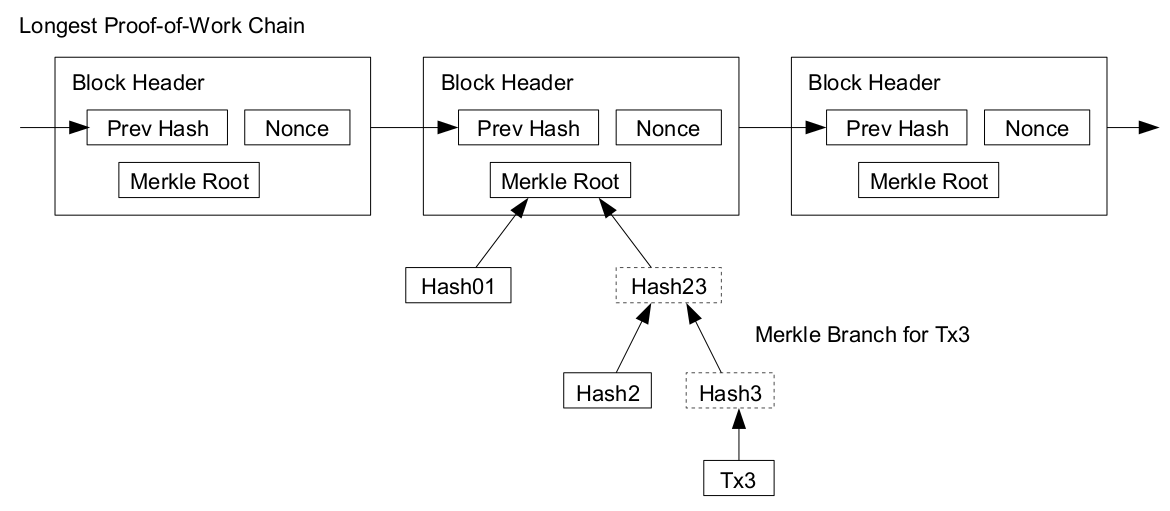
配合这种树结构存储,加上全账本节点(Full nodes)和轻节点(lightweight nodes)的层次,可以缓解现在比特币系统的储存压力。上述分工中全账本节点需要保存所有交易明细,这个储存量从2016年初的50G,到2017年的100G,再到现在150G,在以每年50G的速度增长,预计到2019年会超过200G。而轻节点使用上述Simplified Payment Verification (SPV),只需自己储存空间很小的区块头,然后到全节点获取和某个交易相关的哈希路径,并计算Merkle Root就可以完成交易确认。
基于终态而非日志
存储结构固定以后,网络的同步方式有多种。传统数据库的主从分库,是通过binlog这样事务安全型日志来保证分库间的数据一致。这也是区块链保留所有交易记录为基础的原因。但在所有的历史交易里,对未来有意义的只有那些没被花掉的余额Unspent Transaction Output (UTXO)。比特币的这种记录数量有5000多万,dbSize不到3GB。基于这样的账户快照,就可以极大的清理储存空间。QTUM是支持UTXO账户模式的智能合约平台,算是对比特币和以太坊的一次整合。为了克服兼容的冲突,加入了账户抽象层,将UTXO模型转换成可供EVM执行的账户模型。并提供通用的Consensus-critical coin picking,但所有这些优化都集中在交易层。
Nervos项目是对EVM终态更彻底的整合,其状态机更新基于状态结果而非日志事件。从创始人Jan的访谈里可以看出,他们虽然从以太坊开发者社区来,但是对比特币的POW基础和能力推崇至极。项目底层Common Knowledge Base (CKB) 的目标是优化存储和计算,通过分级客户端,使其运行在轻设备甚至移动设备上。状态程序类叫做Cell,类似UTXO,每次更新需要先复制再修改。区块参与者分 Validator, Generator的分工,遵循新的混合共识机制,支持并行优化和匿名优化。设计思路基于这样的事实:计算出答案和验证答案的复杂度差异很大。比如排序复杂度在,而验证结果的复杂度只有。当计算和验证分工解耦之后,其对应的计算关系需要事先建立,所以Cell的Type是事先约定的。当然一系列的优化,其目标是综合性能,而非单一的空间扩展。
除了上述基于性能优化的主动改变之外,还在进化中的IOTA也会被动频繁的快照清理空账户,因为他的一次性签名不能重复使用,导致大量的弃用地址。但不论动机如何,综合来看,就交易数据本身而言,已经足够紧凑。随着Layer2交易通道的开启,多元交易平台的组合,以及硬件设备本身的进化,交易的数据储存不再是区块链社区的核心痛点。更重要的存储问题,在于和交易关联的服务与应用的数据管理。
半中心化的混合区块云
当所要储存的不单是账本,而是大文件或者数据资源时,区块链真正的痛点来了。让每个全节点重复保存所有文件显然不可能,这里最简单粗暴的方法是文件仍然储存在云平台的云存储上,而文件内容的哈希特征值保存在区块链进行所有权记录和交易。知识产权验证的区块链项目都使用该方法,将图片或者文章转换为特征值上链。即使云平台的图片或原文丢失,只要有人能够补充提供,并且通过哈希特征检查,就可以确认作品的所有权。我们将这种模式概括为双层结构的云上区块链,其中对云并不是强依赖,所以整个系统仍然保持去中心化特性。
当要存储的是隐私文件时,可以将哈希特征上链,但文件本身不能直接上传云平台,需要在存储之前进行加密。这种先加密,再上传,最后记录区块并执行交易的方式概括为三层结构的夹心区块链。这就要求用户钱包app同时具备区块链账户交易和文件加密的功能,这种模式在大数据行业有广泛应用。以车联网为例,每辆行驶的汽车会产生大量行驶轨迹数据,该数据所有权归用户所有,并且可以直接定位到用户位置,非常敏感。用户需要在车机端就完成数据的加密,在数据使用时又需要用户客户端的解密和授权。CarChain车链项目就是按此模式设计,通过手机钱包对车载系统进行绑定和设置,行驶数据以Key-Value模式推送到HBase这类分布式高性能数据库。其中Value进行RSA加密,私钥保存在用户手机钱包里。为了更好的保护隐私,用户钱包以“地址池”形式存在,不同日期的行驶轨迹被打散到不关联的多个地址,防止通过云平台单一地址的信息串联来反推用户。该项目完成了用户端的数据保护,是夹心结构的第一层。夹心结构的第二层是分布式存储,以hadoop的HDFS为例,需要将其中NameNode改造为存储分配的账本和计费依据,而DataNode仍然作为数据存储块分发到存储网路里。夹心结构的第三层是数据权益和交易层,记录数据所有权简单,但是隐私数据的交易和使用仍然是一个遗留问题,需要在安全的计算区或者转化为零知识等价计算以防止数据原文泄露。我们会在后面章节重点讨论该问题。
完全去中心的星际文件系统
不论是双层还是三层结构,都不是完整的区块链,文件存储的责任和激励难以直接植入到区块链经济体系当中。为了解决这个大难题,我们先回顾传统的分布式文件系统是如何设计的。从单一文件系统开始,每个文件都唯一的存储在磁盘上的某个位置,在读写时需要一个文件名称和位置的对应表,相当于一个目录。有了目录和文件,就形成了一套文件系统。如果目录损坏了,或者文件所在的磁盘区损坏了,都会导致文件不可读。所以分布式系统第一步是把文件分散存储,通过设立多个独立的磁盘,把文件复制多份保存,这样即使某个磁盘坏了,还可以从别的磁盘读到。但跨磁盘的管理,需要这个文件目录也同时升级,记录同一个文件在不同磁盘上的位置。除了做文件备份,还可以将超大文件分拆保存。随着这套体系庞大以后,为了优化性能,文件的分块和磁盘分区独立出来成为虚拟的block。以HDFS为例,Block的抽象简化了存储系统,以Block为单位进行复制大大提高了效率。这次虚拟化,也把管理文件的目录Namenode和存放文件块的Datanode区分开,由单一Namenode来分配新文件,由Datanode来分布式存放,既保证了效率,又保证了分布备份。
但这里的Namenode作为单一master节点的话,仍然存在单点故障风险,去中心化并不彻底。简单的做法是给Namenode实时备份,这里必然产生额外的设备和带宽成本,还有一定延迟。另一种做法是减少Namenode的工作内容,HDFS里目前Namenode就只保留文件树,而文件的Block分布在集群中的哪些节点上,是通过Datanode上报得来的。这一做法往前进一步的话,就是把文件树也备份到Datanode上。这样虽然浪费了点空间,但文件和目录都安全了。然而不难发现,新文件进来的时候,还是需要Namenode来单一的拍板决定其存放位置。所以文件的分拆容易,但是高效的统一管理难。这又回到了是否要去中心化的问题,在之前讨论共识机制时,也曾经面临效率和安全的平衡。借用共识机制的DPOS节点选举在这里处理Namenode似乎不太实际,用VRFs减少了交互,但复杂性仍然很高。
那我们把文件分配的任务再简化一下,不需要分析网路情况和block空间,只依据文件的名称和内容,按照固定的block大小强行分拆文件。然后存储节点也唯一的根据其属性建立和文件的映射。这相当于所有节点都是独立的,但是大家完全按照统一的标准配合,在无需主节点的情况下完成文件的分布式存储。这样的方案就是Kademlia。他使用分布式哈希表(DHT)计算每份文件的Key,而这个Key和存储节点的NodeID是生成在相同数值域的,生成规则全网统一即可。任何一个节点接到新文件存储的时候,都先分块、复制并换算这个Key。接着计算该节点上友邻表里和这个Key的异或距离(XOR)最近的NodeID。文件被传送到这个和他更相近的节点,层层传递,直到某个节点NodeID是所有邻居中和文件Key最相近的,就直接储存下来。当要读取文件的时候,直接输入文件的Key,任何节点都能帮你找到存放这个文件的位置,然后上报其储存的内容。
现在解决了去中心化的分配规则,但如果每两个节点间都需要知道彼此的地址,也就是说每一个节点都连接着所有节点的话,那会是一个相当冗余的复杂网络。当有N个节点的时候,网络的连接数为,任意节点间的距离为1。但现实中的人际社会告诉我们,每个人的朋友不需要太多,按六度分隔理论,不超过6个人转介绍,我们就可以认识世界上任何一个人。也就是说存在一个数字k,每个节点只要保存k个邻居的地址,就可以在 次的转移之后,达到这个网络的任何一个点。目前世界上的总人口超过75亿,要满足6度理论的话,理想情况下每人只要有45个朋友就够了。极限情况当K=N的时候,就是最密集的结构,全局信息直接暴露给所有节点,也容易在被攻击时一锅端。这样也有好处是任何一个节点的退出都不影响网络的连接性,但是任何一次信息同步都也会造成整个网络的扰动。另一个极端当K接近1时,每个节点只有一、两个邻居,最坏的情况下,要经过所有节点转介绍,才能到达那个最远的节点。这种网络是非常脆弱的,某几个节点断开都可能导致网络失效。当k取值合适的时候,就生成了一个小世界网络(Small-world network)。
计算机里的世界都是2进制的,所以构造这个网络反而容易。我们令NodeID和Key的二进制地址长度为D,那么可以容纳的内容量和节点量就都是。我们把从低位到高位的2进制数位看成不同的年级,最低那个年级的0和1只能存放2个节点,而最高那个年级的0和1则分别代表了整个网络的两半。Kademlia的k-bucket路由表,就是记录了每个年级离自己最近的那个邻居,一共D个。从低到高,这个二进制表实际上就是一个高度为D的二叉树。任何一次查找的复杂度,都和起始节点的高度有关,类似二分查找的情况,能保证在次查找下找到任何一个节点。平均情况下也已经从数学上证明查找复杂度为 。同时我们观察到,最坏情况离平均情况不远,得到很好的控制。所以Kademlia的路由效率是标准的小世界网络。在此基础上如果抛开所有节点平等的假设,在邻居数量服从幂律分布的小世界网络里,可能通过一些高通量的中继站,进一步缩小网络的平均距离。这里我们再次看到了去中心化和效率间的平衡。
有了Kademlia的网络,加上BitTorrent的传输层,就是完整的去中心化文件系统。免去了种子文件的麻烦。只要知道文件的哈希地址,就可以从任何节点下载文件。后来又加入了Git的版本管理,形成现在的星际文件系统 InterPlanetary File System (IPFS)。该系统就像鸡尾酒,调和了各种工具的优点,整合在一个统一的文件系统框架内。IPFS自己还在不断进化,其中下载速率,垃圾文件清理等等问题都还存在。但缺失的最大一块拼图,是激励机制。BT下载是按照网络上传贡献来换取下载资源的,但IPFS的文件系统对帮你保存文件的人没有有效的支付方式,导致现在大量文件隔天就会被清理。当然你也可以以物换物,只要你自己有储存节点挂在IPFS网络里,并且PIN到你上传的某个文件,那作为交换,这个文件就会在你的节点在线期间,安全存储在网络里。这么做似乎太原始,门槛也有点高,到目前为止IPFS还远达不到中心化云存储的效率和便捷性。
为此IPFS的创始人Juan Benet 发起了filecoin项目,希望将区块链的激励机制进一步整合到IPFS系统里。我们说过凡事要诉诸利益,而非理性。有了激励机制以后,可以带动大量的闲置存储资源上链,在供应充足的情况下,网络协作效应会导致成本大大降低,安全性极大提升。可以预见这个文件系统有望成为主流,甚至替代现在流行的云存储。所以在2017年8月对外融资时,成为当时公募金额最大的ICO(除了私下发行的Telegram以外):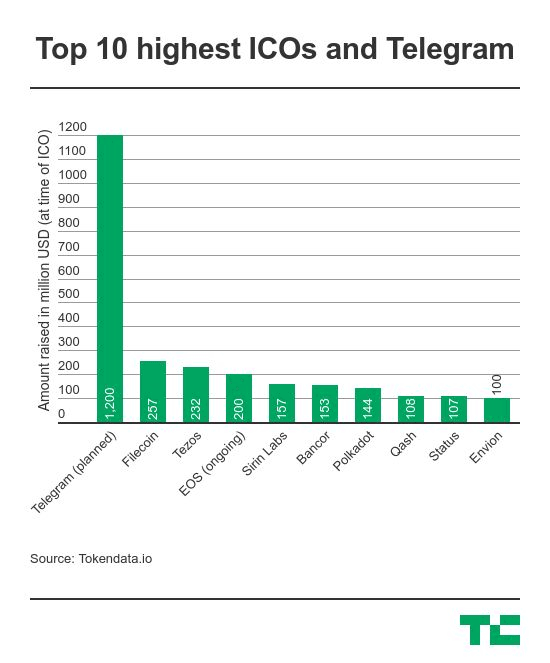
在给予激励前,要先验证存储,最直觉的方式就是抽查。不定期的随机调取文件的某个片段,所有储存了这个片段的节点上报结果进行匹配。正确的给予奖励,错误的奖励清零。但何为正确、何为错误?在完全去中心化的网络里,每一个节点都不能完全信赖,其中的拜占庭容错和区块链交易共识面临的问题完全一样。所以有了POW,POS等等共识机制的差别,在文件系统里,我们追求的是空间贡献的公平。Filecoin设计里的存储方会提供Proofs-of-Storage (PoS) 证明。为了验证和计费,还需要进一步Proof-of-Spacetime (PoSt) 。在Filecoin最新文档里使用叫Proof-of-Replication (PoRep)的共识机制,由其他区块链节点来验证该证明,中间经过挑战和响应的交互过程。通过序列化的PoRep,可以递归证明该文件累计的存储时间POSt。整个过程还依赖zk-SNARKs的匿名验证以及Seal操作。听上去就很复杂,更别说要保证效率会有多难了。为了让这个复杂的流程在区块链上运行,交易过程分为储存和读取两个交易市场,以针对性的协调矿工合作。该项目ICO已经过了一年,每季度的官方博客汇报很久不更新了,github上代码说是合并在ipfs项目里,但看不出有什么进展。